Solutions
Speech
Speech intelligence that passes the human test.
Frontier transcription, voice synthesis, and voice agents for natural, expressive, nuanced interactions with voice AI.
Three core voice AI solutions for any conversation.
Voice agents
Text-to-speech

Speech-to-text
Why Mistral Speech?
Voice generation and replication that captures personality, rhythm, and emotional dexterity.
Transcription that stays accurate in noisy, real-world conditions and knows who said what.
Nine languages for voice generation, thirteen for transcription, with cross-lingual and dialect adaptation.

Open weights, domain fine-tuning, and on-prem deployment. Full control over every component in the pipeline.
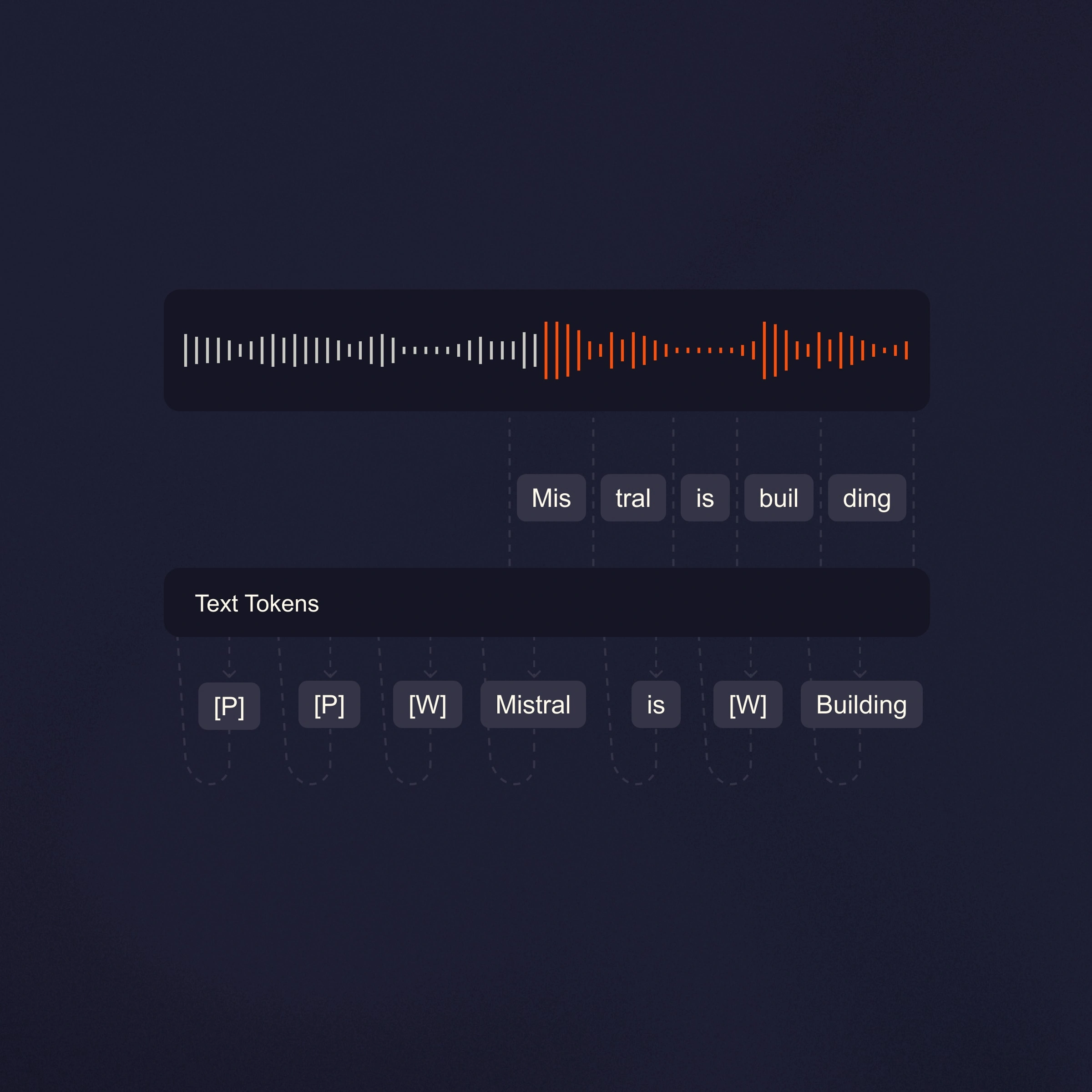
How teams use Mistral Speech today.
By use case.
Customer support.
Voice agents that route and resolve queries across channels with natural, brand-appropriate speech.

Compliance.
Real-time call monitoring with speaker attribution, KYC/AML automation, and auditable interaction records.
Supply chain and logistics.
Voice-enabled shipment tracking, customs coordination, and exception handling across languages.
Sales and marketing.
Meeting intelligence with speaker attribution, pipeline analysis, and automated follow-ups.
Real-time translation.
Cross-lingual voice adaptation for live translation, preserving speaker identity and accent.
By industry.
Financial services.
Compliant voice AI for wealth management advisory, insurance policy queries, and client onboarding.
Manufacturing and industrial operations.
Voice interfaces for quality inspection, production feedback, and field operations in high-noise environments.
Public services and government.
Dialect-specific voice assistants for citizen services, deployed on sovereign infrastructure.
Automotive and in-vehicle systems.
Lightweight on-device models powering voice interfaces without cloud dependency.
Closing the loop on speech intelligence.
Voice agents.
Speak and be heard.
Real-time voice-to-voice conversations that listen, reason, and respond with your brand's voice, tone, and domain knowledge.
Take what you need.
Composable solutions you can run end-to-end, or slot into your existing STT + LLM stack.
Text-to-speech.
Find your voice.
Emotionally expressive speech that captures a speaker's personality. Choose from preset voices, or build your own.
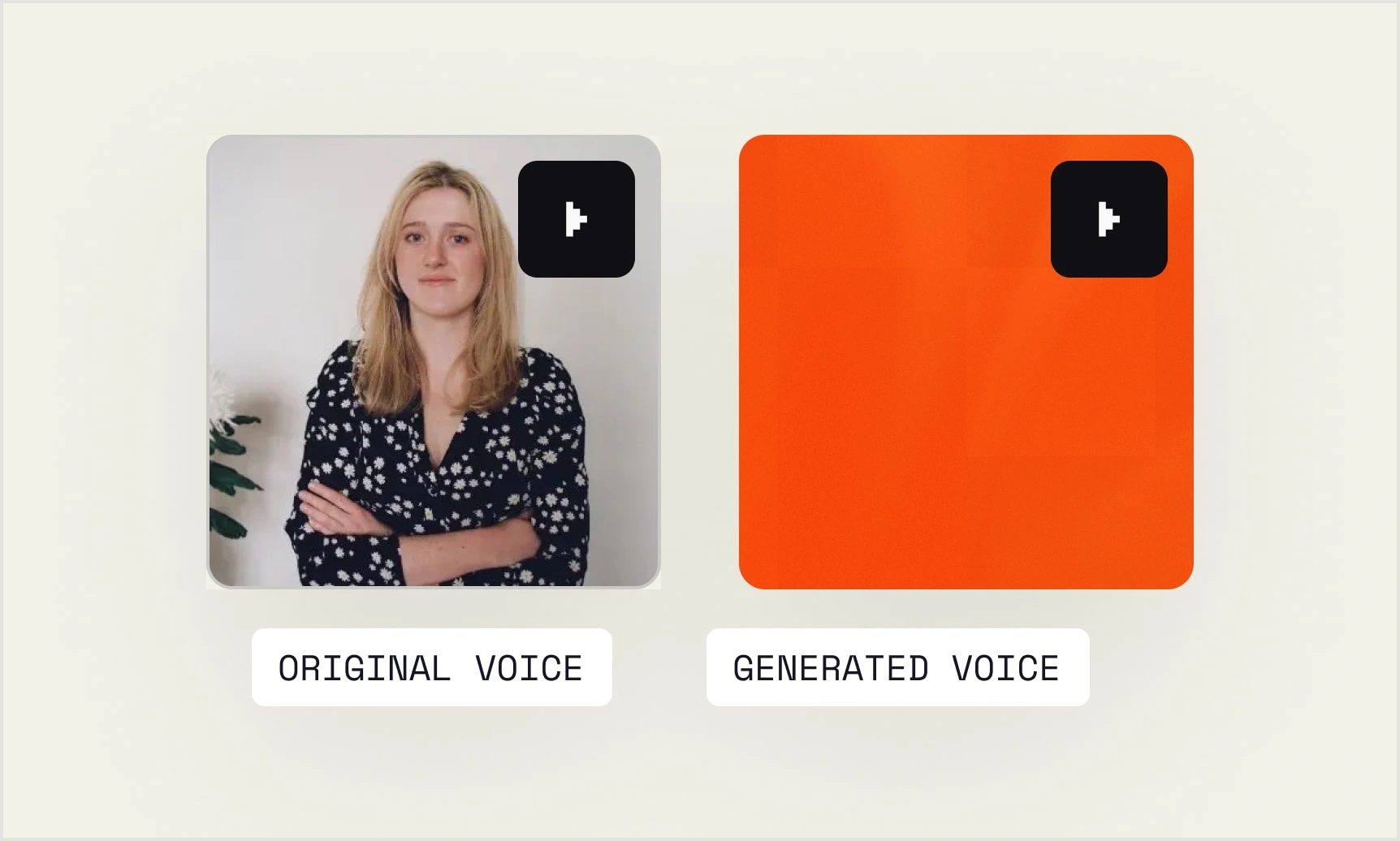
Voice cloning.
Replicate any voice from a sample as short as 3 seconds, capturing tone, rhythm, and personality. Generate speech in a language the speaker never spoke, with their accent and identity intact.
Speech-to-text.
Stream it or send it.
Real-time transcription with sub-200ms latency, or batch transcription of hours-long recordings with structured outputs.
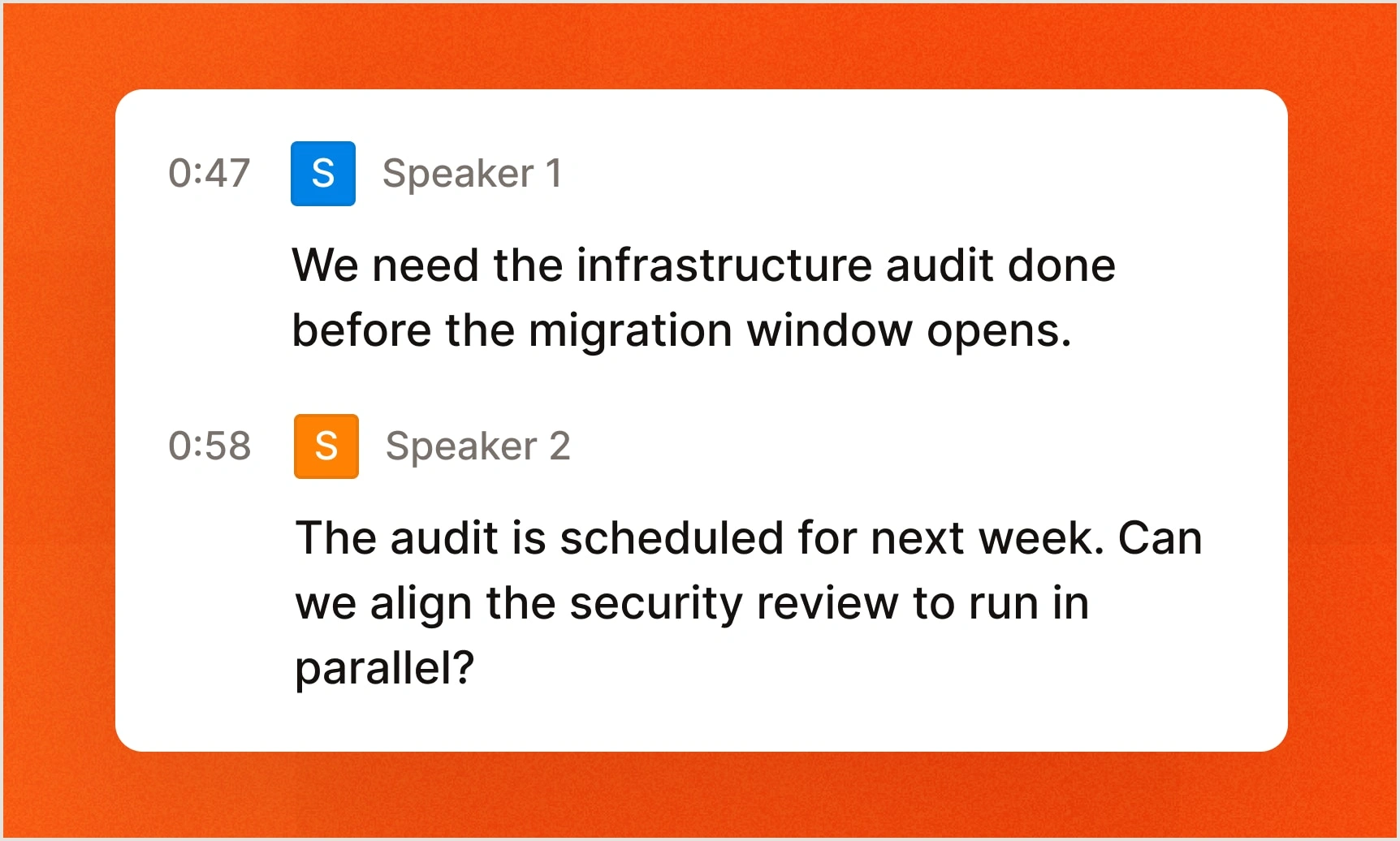
Transcripts that understand.
Speaker diarization captures who said what, with timestamps. Context biasing supports up to 100 custom terms, so it understands your language.
Get started with Mistral Speech.
Frequently asked questions.
Try voice generation and transcription in the Audio Playground in Mistral Studio, integrate via API, or download open weights to self-host.
Yes, two. Voxtral Mini Transcribe 2 for batch transcription with speaker diarization and context biasing and Voxtral Realtime for live streaming transcription with sub-200ms latency.
Yes, you can provide a voice sample as short as 3 seconds and Voxtral TTS, our text-to-speech model, will adapt to capture the speaker's tone, rhythm, and personality. You can also use preset voices or build your own voice library.
Transcription supports 13 languages including English, French, German, Spanish, Chinese, Hindi, Arabic, Portuguese, Russian, Japanese, Korean, Italian, and Dutch. Voice generation supports 9 languages with dialect-aware expressions in English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
An example of combining Voxtral models to form a speech-to-speech pipeline is: Voxtral Realtime transcribes incoming speech, another Mistral LLM reasons over the transcript and determines a response, and Voxtral TTS generates spoken output. Each component is independently customizable and deployable. Cross-lingual voice adaptation means the pipeline can also handle live translation while preserving the speaker's accent and identity.
Yes, you can self-host Mistral Speech or deploy on Mistral Compute.